大数据面试题
老掉牙的问题了,还在这里老生常谈:List特点:元素有放入顺序,元素可重复 ,Set特点:元素无放入顺序,元素不可重复。
1-2)数据库的三大范式?原子性、一致性、唯一性
第一范式:确保每列的原子性
第二范式:在第一范式的基础上更进一层,目标是确保表中的每列都和主键相关.
第三范式:在第二范式的基础上更进一层,目标是确保每列都和主键列直接相关,而不是间接相关.
或者这样说:
第一范式:列不可分,列无二意性;第二范式:主键唯一,不存在多个属性的主键;第三范式:唯一依赖主键,不存在传递依赖
1-3)java的io类的图解 1-4)对象与引用对象的区别对象就是好没有初始化的对象,引用对象即使对这个对象进行了初始化,这个初始化可以使自己的直接new的也可以是直接其他的赋值的,那么背new或者背其他赋值的我们叫做是引用对象,最大的区别于
1-5)谈谈你对反射机制的理解及其用途?反射有三种获取的方式,分别是:forName / getClass /直接使用class方式 使用反射可以获取类的实例
1-6)列出至少五种设计模式设计方式有工厂法,懒加载,观察者模式,静态工厂,迭代器模式,外观模式、、、、
1-7)RPC原理?Rpc分为同步调用和一部调用,异步与同步的区别在于是否等待服务器端的返回值。Rpc的组件有RpcServer,RpcClick,RpcProxy,RpcConnection,RpcChannel,RpcProtocol,RpcInvoker等组件,
1-8)ArrayList、Vector、LinkedList的区别及其优缺点?HashMap、HashTable的区别及优缺点?ArrayList 和Vector是采用数组方式存储数据的,是根据索引来访问元素的,都可以
根据需要自动扩展内部数据长度,以便增加和插入元素,都允许直接序号索引元素,但
是插入数据要涉及到数组元素移动等内存操作,所以索引数据快插入数据慢,他们最大
的区别就是 synchronized同步的使用。
LinkedList 使用双向链表实现存储,按序号索引数据需要进行向前或向后遍历,但
是插入数据时只需要记录本项的前后项即可,所以插入数度较快!
如果只是查找特定位置的元素或只在集合的末端增加、移除元素,那么使用 Vector
或 ArrayList都可以。如果是对其它指定位置的插入、删除操作,最好选择LinkedList
HashMap、HashTable的区别及其优缺点:
HashTable 中的方法是同步的 HashMap 的方法在缺省情况下是非同步的 因此在多线程环境下需要做额外的同步机制。
HashTable 不允许有null值key和value都不允许,而HashMap允许有null值key和value都允许 因此HashMap使用containKey()来判断是否存在某个键。
HashTable 使用 Enumeration ,而HashMap使用iterator。
Hashtable 是 Dictionary 的子类,HashMap是Map接口的一个实现类。
Hadoop相关 1-1)简单概述hdfs原理,以及各个模块的职责1、客户端向 nameNode发送要上传文件的请求
2、nameNode返回给用户是否能上传数据的状态
3、加入用户端需要上传一个 1024M的文件,客户端会通过Rpc请求NameNode,并返回需要上传给那些DataNode(分配机器的距离以及空间的大小等),namonode会选择就近原则分配机器。
4、客户端请求建立 block传输管道chnnel上传数据
5、在上传是 datanode会与其他的机器建立连接并把数据块传送到其他的机器上
6、dataNode向namenode汇报自己的储存情况以及自己的信息
7、档第一个快上传完后再去执行其他的复制的传送
1-2)mr的工作原理1、当执行mr程序是,会执行一个Job
2、客户端的jobClick会请求namenode的jobTracker要执行任务
3、jobClick会去HDFS端复制作业的资源文件
4、客户端的jobClick会向namenode提交作业,让namenode做准备
5、Namenode的jobTracker会去初始化创建的对象
6、Namenode会获取hdfs的划分的分区
7、Namenode去检查TaskTracker的心跳信息,查看存活的机器
8、当执行的datenode执行任务时Datenode会去HDFS获取作业的资源的文件
9、TaskTracker会去执行代码,并登陆JVM的执行渠道
10、JVM或执行MapTask或者ReduceTask
11、执行终结
1-3)怎样判断文件时候存在这是linux上的知识,只需要在IF[ -f ]括号中加上-f参数即可判断文件是否存在
1-4)fsimage和edit的区别?大家都知道namenode与secondary namenode 的关系,当他们要进行数据同步时叫做checkpoint时就用到了fsimage与edit,fsimage是保存最新的元数据的信息,当fsimage数据到一定的大小事会去生成一个新的文件来保存元数据的信息,这个新的文件就是edit,edit会回滚最新的数据。
1-5)hdfs中的block默认保存几份?不管是hadoop1.x 还是hadoop2.x都是默认的保存三份,可以通过参数dfs.replication就行修改,副本的数目要根据机器的个数来确定。
1-6)列举几个配置文件优化?Core-site.xml 文件的优化
fs.trash.interval
默认值: 0
说明: 这个是开启hdfs文件删除自动转移到垃圾箱的选项,值为垃圾箱文件清除时间。一般开启这个会比较好,以防错误删除重要文件。单位是分钟。
dfs.namenode.handler.count
默认值:10
说明:hadoop系统里启动的任务线程数,这里改为40,同样可以尝试该值大小对效率的影响变化进行最合适的值的设定。
mapreduce.tasktracker.http.threads
默认值:40
说明:map和reduce是通过http进行数据传输的,这个是设置传输的并行线程数。
1-7) 谈谈数据倾斜,如何发生的,并给出优化方案数据的倾斜主要是两个的数据相差的数量不在一个级别上,在只想任务时就造成了数据的倾斜,可以通过分区的方法减少reduce数据倾斜性能的方法,例如;抽样和范围的分区、自定义分区、数据大小倾斜的自定义侧咯
1-8)简单概括安装hadoop的步骤1.创建 hadoop 帐户。
2.setup.改 IP。
3.安装 java,并修改/etc/profile 文件,配置 java 的环境变量。
4.修改 Host 文件域名。
5.安装 SSH,配置无密钥通信。
6.解压 hadoop。
7.配置 conf 文件下 hadoop-env.sh、core-site.sh、mapre-site.sh、hdfs-site.sh。
8.配置 hadoop 的环境变量。
9.Hadoop namenode -format
10.Start-all.sh
1-9)简单概述hadoop中的角色的分配以及功能Namenode:负责管理元数据的信息
SecondName:做namenode冷备份,对于namenode的机器当掉后能快速切换到制定的Secondname上
DateNode:主要做储存数据的。
JobTracker:管理任务,并把任务分配到taskTasker
TaskTracker:执行任务的
1-10)怎样快速的杀死一个job1、执行hadoop job -list 拿到job-id
2、Hadoop job kill hadoop-id
1-11)新增一个节点时怎样快速的启动Hadoop-daemon.sh start datanode
1-12)你认为用java , streaming , pipe方式开发map/reduce,各有什么优点开发mapReduce只用过java与hive,不过使用java开发mapreduce显得笨拙,效率也慢,基于java慢的原因于是hive,这样就方便了查询与设计
1-13)简单概述hadoop的join的方法Hadoop 常用的jion有reduce side join , map side join , SemiJoin 不过reduce side join 与 map side join 比较常用,不过都是比较耗时的。
1-14)简单概述hadoop的combinet与partition的区别combine和partition都是函数,中间的步骤应该只有shuffle! combine分为map端和reduce端,作用是把同一个key的键值对合并在一起,可以自定义的,partition是分割map每个节点的结果,按照key分别映射给不同的reduce,也是可以自定义的。这里其实可以理解归类。
1-15 ) hdfs 的数据压缩算法Hadoop 的压缩算法有很多,其中比较常用的就是gzip算法与bzip2算法,都可以可通过CompressionCodec来实现
1-16)hadoop的调度Hadoop 的调度有三种其中fifo的调度hadoop的默认的,这种方式是按照作业的优先级的高低与到达时间的先后执行的,还有公平调度器:名字见起意就是分配用户的公平获取共享集群呗!容量调度器:让程序都能货到执行的能力,在队列中获得资源。
1-17)reduce后输出的数据量有多大?输出的数据量还不是取决于map端给他的数据量,没有数据reduce也没法运算啊!!
1-18) datanode 在什么情况下不会备份?Hadoop保存的三个副本如果不算备份的话,那就是在正常运行的情况下不会备份,也是就是在设置副本为1的时候不会备份,说白了就是单台机器呗!!
1-19)combine出现在那个过程?Hadoop的map过程,根据意思就知道结合的意思吗,剩下的你们就懂了。想想wordcound
1-20) hdfs 得体系结构?NameNode , dataNode , secondary namenode
1-21) hadoop flush 的过程?Flush 就是把数据落到磁盘,把数据保存起来呗!
1-22) 什么是队列队列的实现是链表,消费的顺序是先进先出。
1-23)三个 datanode,当有一个datanode出现错误会怎样?第一不会给储存带来影响,因为有其他的副本保存着,不过建议尽快修复,第二会影响运算的效率,机器少了,reduce在保存数据时选择就少了,一个数据的块就大了所以就会慢。
1-24)mapReduce的执行过程首先map端会Text 接受到来自的数据,text可以把数据进行操作,最后通过context把key与value写入到下一步进行计算,一般的reduce接受的value是个集合可以运算,最后再通过context把数据持久化出来。
1-25)Cloudera 提供哪几种安装 CDH 的方法· Cloudera manager
· Tarball
· Yum
· Rpm
1-26)选择题与判断题 1-27)hadoop的combinet与partition效果图 1-28)hadoop的机架感知(或者说是扩普)看图说话
数据块会优先储存在离namenode进的机器或者说成离namenode机架近的机器上,正好是验证了那句话不走网络就不走网络,不用磁盘就不用磁盘。
1-29)文件大小默认为 64M,改为128M有啥影响?这样减少了namenode的处理能力,数据的元数据保存在namenode上,如果在网络不好的情况下会增到datanode的储存速度。可以根据自己的网络来设置大小。
1-30)datanode首次加入cluster的时候,如果log报告不兼容文件版本,那需要namenode执行格式化操作,这样处理的原因是?这样处理是不合理的,因为那么 namenode 格式化操作,是对文件系统进行格式
化,namenode 格式化时清空dfs/name下空两个目录下的所有文件,之后,会在目
录 dfs.name.dir 下创建文件。
文本不兼容,有可能时 namenode 与 datanode 的 数据里的namespaceID、
clusterID 不一致,找到两个 ID位置,修改为一样即可解决。
1-31)什么 hadoop streaming?提示:指的是用其它语言处理
1-32)MapReduce中排序发生在哪几个阶段?这些排序是否可以避免?为什么?一个 MapReduce 作业由 Map 阶段和Reduce阶段两部分组成,这两阶段会对数
据排序,从这个意义上说,MapReduce 框架本质就是一个 Distributed Sort。在Map
阶段,在 Map 阶段,Map Task会在本地磁盘输出一个按照key排序(采用的是快速
排序)的文件(中间可能产生多个文件,但最终会合并成一个),在 Reduce 阶段,每
个 Reduce Task 会对收到的数据排序,这样,数据便按照 Key 分成了若干组,之后以
组为单位交给 reduce()处理。很多人的误解在Map阶段,如果不使用Combiner
便不会排序,这是错误的,不管你用不用 Combiner,Map Task均会对产生的数据排
序(如果没有 Reduce Task,则不会排序,实际上Map阶段的排序就是为了减轻Reduce
端排序负载)。由于这些排序是 MapReduce 自动完成的,用户无法控制,因此,在
hadoop 1.x 中无法避免,也不可以关闭,但 hadoop2.x是可以关闭的。
Zookeeper 相关 1-1)写出你对zookeeper的理解随着大数据的快速发展,多机器的协调工作,避免主要机器单点故障的问题,于是就引入管理机器的一个软件,他就是zookeeper来协助机器正常的运行。
Zookeeper有两个角色分别是leader与follower ,其中leader是主节点,其他的是副节点,在安装配置上一定要注意配置奇数个的机器上,便于zookeeper快速切换选举其他的机器。
在其他的软件执行任务时在zookeeper注册时会在zookeeper下生成相对应的目录,以便zookeeper去管理机器。
1-2)zookeeper的搭建过程主要是配置文件zoo.cfg 配置dataDir 的路径一句dataLogDir的路径以及myid的配置以及server的配置,心跳端口与选举端口
Hive 相关 1-1)hive是怎样保存元数据的保存元数据的方式有:内存数据库rerdy,本地mysql数据库,远程mysql数据库,但是本地的mysql数据用的比较多,因为本地读写速度都比较快
1-2)外部表与内部表的区别先来说下Hive中内部表与外部表的区别:
Hive 创建内部表时,会将数据移动到数据仓库指向的路径;若创建外部表,仅记录数据所在的路径,不对数据的位置做任何改变。在删除表的时候,内部表的元数据和数据会被一起删除,而外部表只删除元数据,不删除数据。这样外部表相对来说更加安全些,数据组织也更加灵活,方便共享源数据。
1-3)对于 hive,你写过哪些UDF函数,作用是什么UDF: user defined function 的缩写,编写hive udf的两种方式extends UDF 重写evaluate第二种extends GenericUDF重写initialize、getDisplayString、evaluate方法
1-4)Hive 的 sort by和order by的区别order by 会对输入做全局排序,因此只有一个reducer(多个reducer无法保证全局有序)只有一个reducer,会导致当输入规模较大时,需要较长的计算时间。
sort by不是全局排序,其在数据进入reducer前完成排序.
因此,如果用sort by进行排序,并且设置mapred.reduce.tasks>1, 则sort by只保证每个reducer的输出有序,不保证全局有序。
Hbase 相关 1-1)Hbase的rowkey怎么创建比较好?列族怎么创建比较好?Rowkey是一个二进制码流,Rowkey的长度被很多开发者建议说设计在10~100个字节,不过建议是越短越好,不要超过16个字节。
Rowkey散列原则 、 Rowkey唯一原则 、针对事务数据Rowkey设计 、针对统计数据的Rowkey设计 、针对通用数据的Rowkey设计、支持多条件查询的RowKey设计
1-2)Hbase的实现原理Hbase 的实现原理是rpcProtocol
1-3) hbase 过滤器实现原则感觉这个问题有问题,过滤器多的是啦,说的是哪一个不知道!!!!
Hbase的过滤器有:RowFilter、PrefixFilter、KeyOnlyFilter、RandomRowFilter、InclusiveStopFilter、FirstKeyOnlyFilter、ColumnPrefixFilter、ValueFilter、ColumnCountGetFilter、SingleColumnValueFilter、SingleColumnValueExcludeFilter、WhileMatchFilter、FilterList
你看这么多过滤波器呢,谁知道你问的那个啊!!
比较常用的过滤器有:RowFilter 一看就知道是行的过滤器,来过滤行的信息。PrefixFilter前缀的过滤器,就是把前缀作为参数来查找数据呗!剩下的不解释了看过滤器的直接意思就OK了很简单。
1-4)描述 HBase, zookeeper搭建过程Zookeeper 的问题楼上爬爬有步骤,hbase主要的配置文件有hbase.env.sh主要配置的是JDK的路径以及是否使用外部的ZK,hbase-site.xml 主要配置的是与HDFS的链接的路径以及zk的信息,修改regionservers的链接其他机器的配置。
1-5)hive如何调优?在优化时要注意数据的问题,尽量减少数据倾斜的问题,减少job的数量,同事对小的文件进行成大的文件,如果优化的设计那就更好了,因为hive的运算就是mapReduce所以调节mapreduce的参数也会使性能提高,如调节task的数目。
1-6)hive的权限的设置Hive的权限需要在hive-site.xml文件中设置才会起作用,配置默认的是false,需要把hive.security.authorization.enabled设置为true,并对不同的用户设置不同的权限,例如select ,drop等的操作。
1-7 ) hbase 写数据的原理1. 首先,Client通过访问ZK来请求目标数据的地址。
2. ZK中保存了-ROOT-表的地址,所以ZK通过访问-ROOT-表来请求数据地址。
3. 同样,-ROOT-表中保存的是.META.的信息,通过访问.META.表来获取具体的RS。
4. .META.表查询到具体RS信息后返回具体RS地址给Client。
5. Client端获取到目标地址后,然后直接向该地址发送数据请求。
1-8)hbase宕机了如何处理?HBase的RegionServer宕机超过一定时间后,HMaster会将其所管理的region重新分布到其他活动的RegionServer上,由于数据和日志都持久在HDFS中,
该操作不会导致数据丢失。所以数据的一致性和安全性是有保障的。
但是重新分配的region需要根据日志恢复原RegionServer中的内存MemoryStore表,这会导致宕机的region在这段时间内无法对外提供服务。
而一旦重分布,宕机的节点重新启动后就相当于一个新的RegionServer加入集群,为了平衡,需要再次将某些region分布到该server。
因此,Region Server的内存表memstore如何在节点间做到更高的可用,是HBase的一个较大的挑战。
Hbase的metastore是用来保存数据的,其中保存数据的方式有有三种第一种于第二种是本地储存,第二种是远程储存这一种企业用的比较多
1-10)hbase客户端在客户端怎样优化?Hbase使用JAVA来运算的,索引Java的优化也适用于hbase,在使用过滤器事记得开启bloomfilter可以是性能提高3-4倍,设置HBASE_HEAPSIZE设置大一些
1-11)hbase是怎样预分区的?如何去进行预分区,可以采用下面三步:
1.取样,先随机生成一定数量的rowkey,将取样数据按升序排序放到一个集合里
2.根据预分区的region个数,对整个集合平均分割,即是相关的splitKeys.
3.HBaseAdmin.createTable(HTableDescriptor tableDescriptor,byte[][] splitkeys)可以指定预分区的splitKey,即是指定region间的rowkey临界值
不能使用 sqoop,速度太慢了,提示如下:
A、一种可以加快批量写入速度的方法是通过预先创建一些空的 regions,这样当
数据写入 HBase 时,会按照 region 分区情况,在集群内做数据的负载均衡。
B、hbase 里面有这样一个 hfileoutputformat类,他的实现可以将数据转换成 hfile
格式,通过 new 一个这个类,进行相关配置,这样会在 hdfs 下面产生一个文件,这个
时候利用 hbase 提供的 jruby 的 loadtable.rb 脚本就可以进行批量导入。
1-13)谈谈 HBase集群安装注意事项?需要注意的地方是 ZooKeeper 的配置。这与 hbase-env.sh 文件相关,文件中
HBASE_MANAGES_ZK 环境变量用来设置是使用 hbase默认自带的Zookeeper还
是使用独立的 ZooKeeper。HBASE_MANAGES_ZK=false时使用独立的,为true时
使用默认自带的。
某个节点的 HRegionServer 启动失败,这是由于这 3 个节点的系统时间不一致相
差超过集群的检查时间 30s。
1-14)简述 HBase的瓶颈Hbase主要的瓶颈就是传输问题,在操作时大部分的操作都是需要对磁盘操作的,
环境配置 1-1)你们的集群规模?这个得看个人在公司的规模,下面介绍一下我们公司的一些配置:
联想System x3750 服务器,价格3.5万,内存容量32G,产品类型机架式,硬盘接口SSD,CPU频率2.6GH,CPU数量2颗,三级缓存15MB,cpu核心6核,cpu线程数12线程,最大内存支持1.5T,网络是千兆网卡,可插拔时硬盘接口12个卡槽,配置1T的容量
详细:
名字 软件 运行管理
Hadoop1 JDK,hadoop namenode
Hadoop2 JDK,hadoop namenode
Hadoop3 JDK,hadoop secondaryNamenode
Hadoop4 JDK,hadoop secondaryNamenode
Hadoop5 JDK,hadoop datanode
Hadoop6 JDK,hadoop datanode
Hadoop7 JDK,hadoop datanode
Hadoop8 JDK,hadoop datanode
Hadoop9 JDK,hadoop datanode
Hadoop10 JDK,zookeeper,tomcat,mvn,kafka leader
Hadoop11 JDK,zookeeper,tomcat,mvn,kafka follower
Hadoop12 JDK,zookeeper,tomcat,mvn,kafka follower
Hadoop13 JDK,hive,mysql,svn,logstarh hive,mysql,svn
Hadoop14 JDK,hbase,mysql备份 datanode
Hadoop15 JDK,nginx,Log日志手机 datanode
数据就是每天访问的Log日志不是很大,有的时候大有的时候小的可怜
1-2)你在项目中遇到了哪些难题,是怎么解决的?1、在执行任务时发现副本的个数不对,经过一番的查找发现是超时的原因,修改了配置文件hdfs-site.xml:中修改了超时时间。
2、由于当时在分配各个目录空间大小时,没有很好的分配导致有的目录的空间浪费,于是整体商量后把储存的空间调大了一些。
相关热词:
本站内容来源于网络,如有侵权请与我们联系,我们会及时删除,我们深感抱歉!
注:本站所有信息仅供用于网络技术学习参考,学习中请遵循相关法律法规!
本文地址: https://v30.fanwenzhu.com/sql/nosql/10858.shtml
相关文章
热门TAG
win10 ecshop 主机 阿里云 解决 配置 C# C++ 解析 SQL语句 命令 Go语言 方法 CSS3 HTML5 CSS win7 MSSQL 服务器配置 IIS7.5 IIS7 IIS6 IIS CentOS 7 Linux oracle数据库 oracle phpcms discuz discuz教程最新文章
-
 3NF(无依赖):主键字段
3NF(无依赖):主键字段
时间:2021-01-22
-
 进修Redis你必需相识的数据
进修Redis你必需相识的数据
时间:2021-01-22
-
 领略OVER子句
领略OVER子句
时间:2021-01-22
-
 MongoDB的查询操纵
MongoDB的查询操纵
时间:2021-01-22
-
 动态加载就动态加载了吧
动态加载就动态加载了吧
时间:2021-01-22
-
 数据库理相关常识
数据库理相关常识
时间:2021-01-14
-
 存储进程实现可扩展机动
存储进程实现可扩展机动
时间:2021-01-14
-
 通过计算出的hashkey
通过计算出的hashkey
时间:2021-01-14
热门文章
-
 SpringMvc+Mybatis+Redis框架
SpringMvc+Mybatis+Redis框架
时间:2020-12-27
-
 CentOS6.5_X64下安装配置MongoDB数据库
CentOS6.5_X64下安装配置MongoDB数据库
时间:2021-01-07
-
 Redis学习笔记一
Redis学习笔记一
时间:2021-01-06
-
 大数据架构的典型方法和方式
大数据架构的典型方法和方式
时间:2021-01-07
-
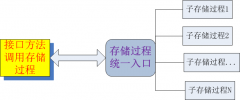 存储过程实现可扩展灵活接口
存储过程实现可扩展灵活接口
时间:2020-12-27
-
 两大数据库缓存系统实现对比
两大数据库缓存系统实现对比
时间:2020-12-27
-
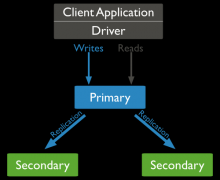 MongoDB 搭建副本集
MongoDB 搭建副本集
时间:2021-01-03
-
 玩转mongodb(七):索引,速度的引领(全
玩转mongodb(七):索引,速度的引领(全
时间:2021-01-06
-
 如何使用DB查询分析器高效地生成旬报货
如何使用DB查询分析器高效地生成旬报货
时间:2021-01-06
-
 c#之Redis队列在邮件提醒中的应用
c#之Redis队列在邮件提醒中的应用
时间:2021-01-03